20260612汇报
Multimodal Wildland Fire Smoke Detection
基于卫星、天气传感器和光学相机图像的多模式野地火灾烟雾探测的多模式SmokeyNet和SmokeyNet集成。
网络结构
SmokeyNet
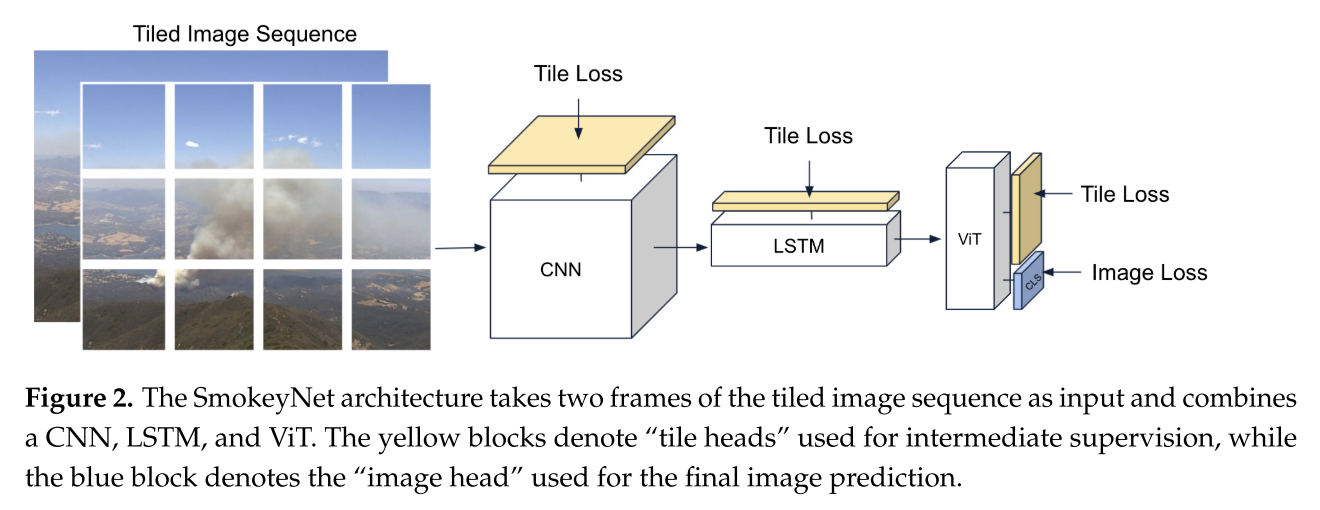
(1)第一层:CNN 模块 —— 单帧局部空间特征提取
- 骨干网络:选用ResNet34(轻量版 ResNet50),基于 ImageNet 预训练权重初始化,兼顾特征能力与推理速度。
- 执行逻辑:
- 两帧图像的每一个 224×224 子图,单独送入 ResNet34提取深度视觉特征;
- 输出每个子图的高维空间特征向量,仅捕捉单帧画面里烟雾的颜色、纹理、形态等静态空间特征。
(2)第二层:LSTM 模块 —— 跨帧时序特征融合
烟雾是动态目标,单帧特征不足以区分雾、云与烟雾,LSTM 专门建模帧间运动与时序变化。
执行逻辑:
- 按位置配对:将当前帧子图特征与前一帧同位置子图特征输入 LSTM;
- LSTM 学习相邻帧之间烟团的移动、扩散、形态变化等时序信息,输出融合时空信息的子图特征。
附属结构:
LSTM 子图分类头:结构与 CNN 子图头完全一致,对 LSTM 输出的时序特征做子图级二分类,再次施加中间监督。
(3)第三层:ViT(视觉 Transformer)模块 —— 全局空间关联融合
单张子图特征是局部信息,ViT 负责把所有子图特征关联起来,建模整张图像的全局空间关系。
执行逻辑:
将 45 个经过 LSTM 编码的子图特征,作为 Transformer 的 “序列 Token” 输入 ViT;
ViT 通过自注意力机制,学习不同位置子图之间的关联(比如连片烟团、烟雾蔓延区域);
ViT 输出两类特征:
① 每个子图对应的新特征;
② 特殊 CLS Token:聚合整幅图像所有子图的全局摘要特征,用于最终全局判定。
附属结构:
ViT 子图分类头:对 ViT 输出的单子图特征做二分类,第三层中间监督;
图像分类头(Image Head)
:模型最终输出分支
- 输入:ViT 的 CLS 全局特征;
- 结构:3 层全连接(输出维度依次 256→64→1)+ Sigmoid 激活;
- 输出:整张图像是否存在野火烟雾的全局二分类结果(阈值 0.5)。
Tile loss(子图损失 / 分块损失) 是针对图像切分后的每个Tile(子图 / 图像块) 计算的损失函数,属于中间监督损失。
对每一个子图的预测结果与对应真实标签计算得到的损失,统称为 Tile loss。
与之相对的是 Image loss(图像损失):针对整张原图最终预测结果计算的全局损失。
Multimodal SmokeyNet
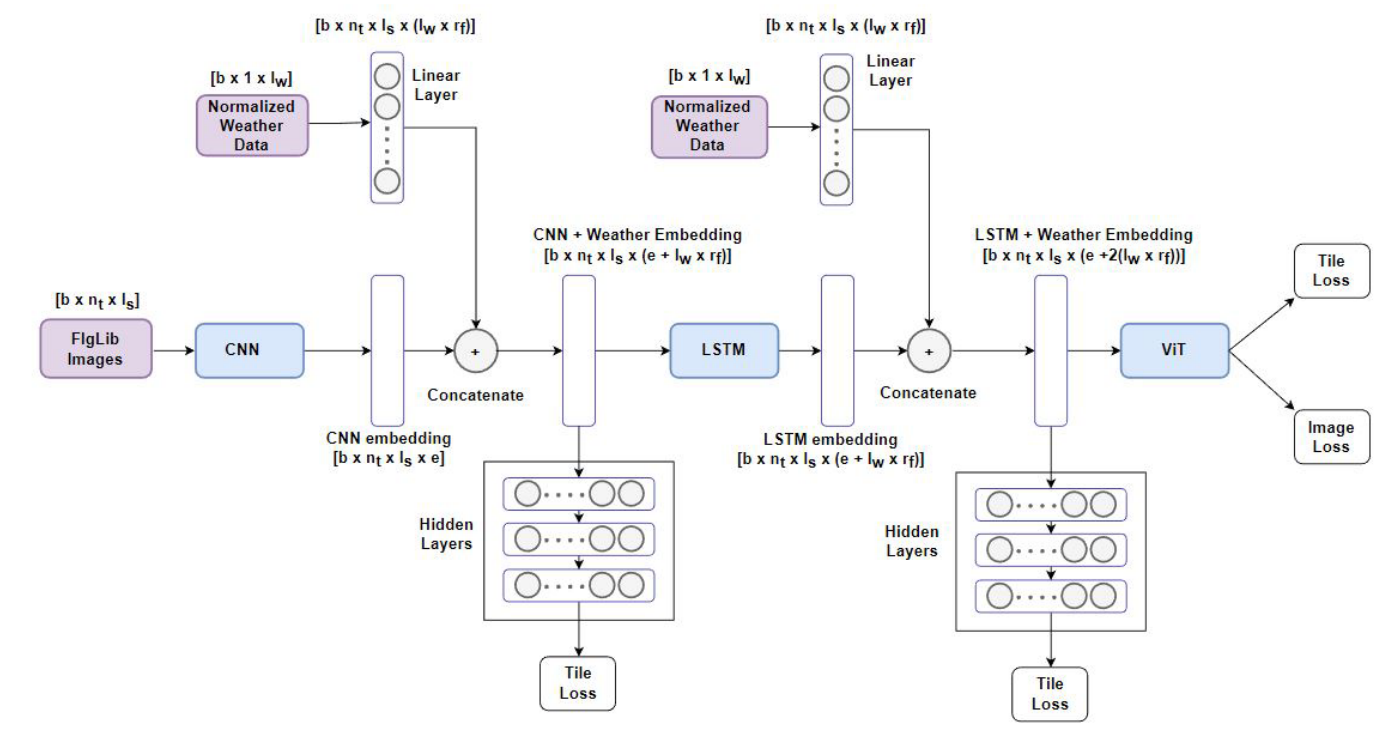
气象数据向量变化
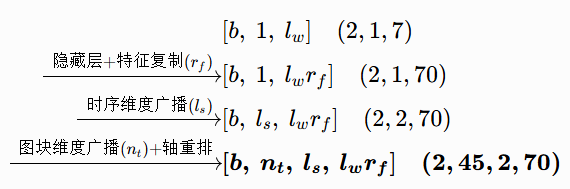
为什么要用广播而不是真实复制数据? 气象描述整段场景的全局环境:
- 同一批次、同一帧、同一张图的所有 45 个图块,气象数据完全一致;
- 广播是框架(PyTorch/TensorFlow)的内存优化机制,不额外拷贝数据,仅在计算逻辑上扩展维度,保证效率。
两处融合的复用逻辑
变换完成后的$ $ 气象张量:
- 第一次:和 CNN 输出视觉特征拼接;
- 第二次:该气象张量直接复用,再和 LSTM 输出视觉特征拼接;
全程只做一次维度变换,不用重复计算气象分支。
为什么引入rf?
- 不引入的话,气象维度为7,会被1000维的视觉特征稀释。
为什么进行第二次气象融合?
- LSTM 负责捕捉连续两帧图像之间的变化,建模烟雾飘动、扩散、蔓延等时序动态特征。
- CNN 负责提取单帧图像里烟雾的形态、纹理、轮廓、局部区域等空间视觉特征。
ViT的输出?(豆包)
Tile 输出(图块级预测):对每一个图块单独输出 “有无烟雾” 概率,计算 ViT 阶段图块损失;
Image 输出(全局图像级预测):利用 Transformer 的 CLS token 整合整张图像所有信息,输出整张图片的烟雾二分类结果,计算 Image Loss(图像主损失)。
数据组织格式
气象数据
每张RGB图像对应一条csv记录,每条记录由气温、相对湿度、风速、阵风、风向(sin cos)、露点温度。
解释:
阵风:气象术语,特殊的空气流动现象,指风速在短暂时间内,有突然出现忽大忽小变化的风。通常是指“瞬间极大风速”。
露点温度:指气象学中表示在固定气压条件下,空气内水蒸气达到饱和状态所需冷却至的温度阈值。
图像数据
A RGB-Thermal based adaptive modality learning network for day–night wildfire identification
网络结构
与先前范式对比
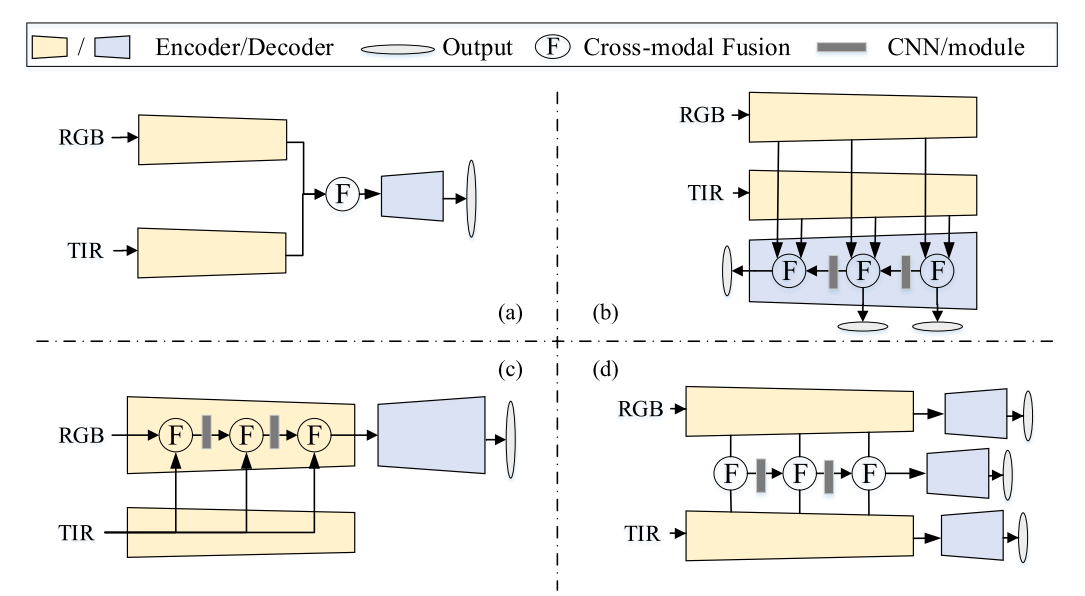
范式a
结构流程
- RGB、TIR 两个模态各自使用一套完整、结构相同的独立网络,分别提取单模态中间特征;
- 两个分支特征提取完成后,在网络后半段统一拼接 / 融合;
- 送入同一个后续网络 / 解码器,输出最终分割结果。
核心特点
- 设计简单,两个模态完全解耦;
- 只学习跨模态共享特征,不区分模态独有信息;
优缺点
✅ 实现容易、分支训练灵活;
❌ 忽略 RGB/TIR 各自的专属特征,模态互补性利用不充分。
范式b
结构流程
- 依然采用双分支提取 RGB、TIR 特征;
- 额外增加专用模块(边缘感知、位置增强、语义增强模块等),针对性挖掘不同层级(高 / 中 / 低层)特征;
- 叠加多种辅助监督信号(边缘监督、位置监督、语义监督),引导模型收敛、提升特征表达能力。
核心特点
- 主打多模块 + 多任务监督,从特征层级和损失约束两方面强化融合效果;
- 依然以学习模态共享特征为主;
- 论文对应模型:LASNet、EGFNet、GMNet 等主流 RGB-T 分割网络。
优缺点
✅ 精度较高,适配复杂场景;
❌ 模块繁多、结构复杂,参数量与计算量大幅增加,不利于边缘设备实时部署。
范式c
结构流程
- 选定RGB 作为主分支网络,承担主要特征提取与分割任务;
- 红外 TIR 分支作为辅助子网络,提取热成像特征;
- 将 TIR 特征逐层级嵌入 RGB 主分支,用红外信息增强、修正 RGB 特征,而非平等融合;
- 最终依靠 RGB 主解码器输出结果。
核心特点
- 典型 “主 - 辅” 模态融合 思路,TIR 仅作为补充;
- 代表模型:RTFNet、FEANet(搭载特征增强注意力模块 FEAM)。
优缺点
✅ 网络逻辑清晰,一定程度弥补 RGB 在弱光下的不足;
❌ 弱化了 TIR 模态本身的价值,夜间、低光照场景上限低;两个模态地位不对等。
范式d
结构流程
- 双编码器:RGB、TIR 并行编码器,分别提取各自多尺度特征(保留模态独有信息);
- 双模态专属解码器:为 RGB、TIR 各设置独立解码器,搭配专属监督,专门学习单模态独有特征;
- 共享解码器:融合两个编码器特征 + 两个专属解码器的输出,学习双模态共享特征;
- 三路独立标签监督:分别对 RGB 解码器、TIR 解码器、共享解码器施加损失约束,端到端协同训练。
核心特点
- 不再只追求 “共享特征”,显式分离模态独有特征与跨模态共享特征;
- 不设计复杂注意力 / 交互模块,网络结构轻量化;
- 依靠多分支解码器 + 多路监督实现自适应模态学习,平衡精度与推理速度;
- 专门针对昼夜野火识别场景设计,充分发挥 RGB(纹理 / 白天)、TIR(抗光照 / 夜间)各自优势。
优缺点
✅ 模态互补性利用充分、泛化能力强、计算开销低,适合无人机 / 地面监控等野外实时设备;
❌ 分支结构比 (a)(c) 略复杂,但远优于 (b) 类重型多模块网络
具体网络架构图
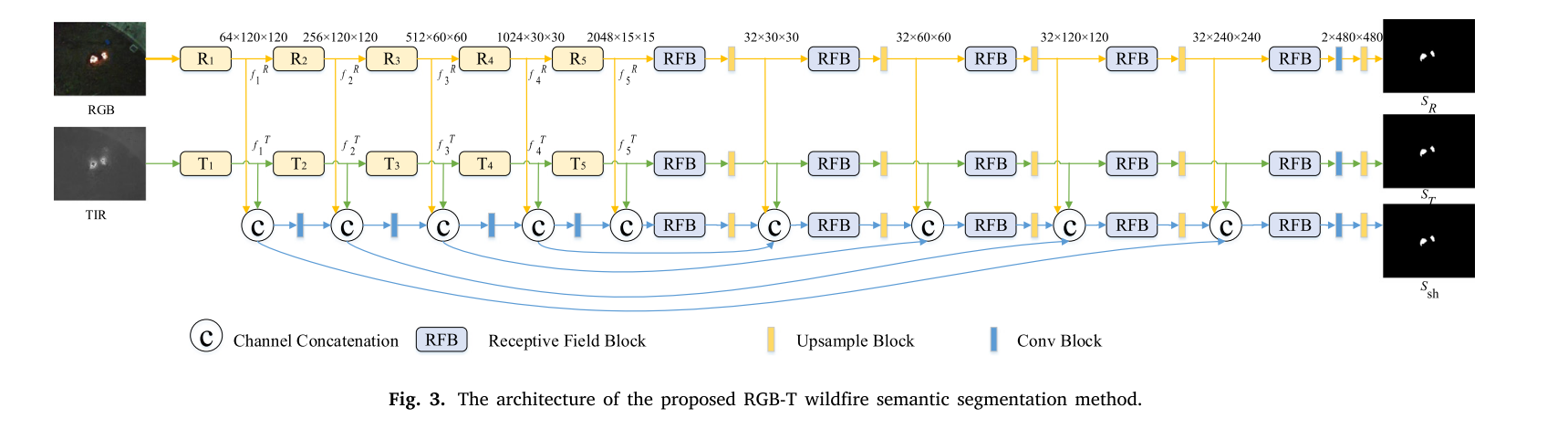
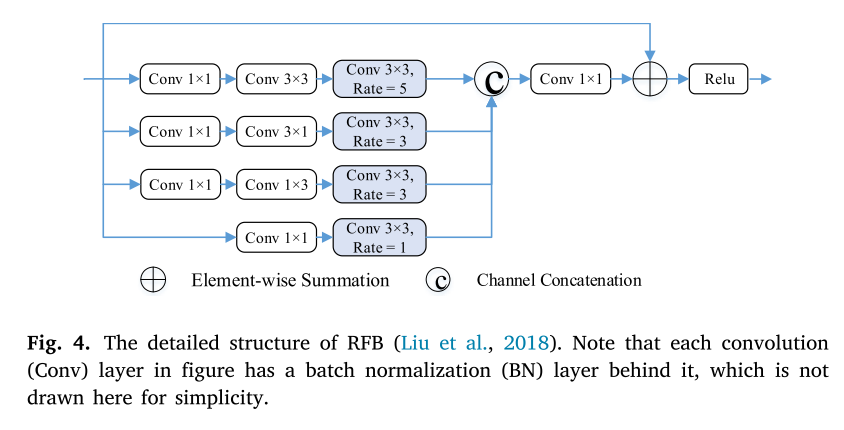
完整网络由双编码器、三类解码器、RFB 特征增强模块、多分支监督损失四部分组成,为端到端训练结构:
- 双并行编码器:分别对 RGB 图像、TIR 热红外图像做多尺度特征提取;
- 特征融合层:编码器中间层特征做通道拼接,得到 RGB-T 共享融合特征;
- 三大解码器:RGB 独有解码器、TIR 独有解码器、跨模态共享解码器(最终输出预测结果);
- 三重独立监督:三个解码器分别对应标签损失,引导网络同时学习单模态专属特征与双模态共有特征;
- 核心组件:RFB(感受野模块)用于捕捉多尺度、上下文信息,适配不同尺度火焰目标。
整体流程:RGB/TIR 图像分别送入编码器 → 提取单模态多尺度特征 → 特征分流至模态独有解码器 + 融合后送入共享解码器 → 三个解码器分别输出分割结果 → 联合损失函数反向传播优化。
RFB模块